Behavioral protection
It watches what software does, not what it claims to be. Instead of waiting for known malware signatures, QuickSecure looks for dangerous behavior as it happens.
Built after a real targeted attack.
AI-powered endpoint protection for teams that need strong security without the noise — from a single laptop to an enterprise fleet.
Free for one device. No credit card. Takes about a minute.
No action needed
What it does
QuickSecure watches behavior, acts quietly, and keeps protection lightweight.
It watches what software does, not what it claims to be. Instead of waiting for known malware signatures, QuickSecure looks for dangerous behavior as it happens.
When QuickSecure sees dangerous activity, it reacts in milliseconds, explains what happened in plain language, and lets you reverse anything you didn't authorize. Three operating modes — Shadow, Supervised, Autonomous — so trust is earned, not assumed.
Built to protect without slowing the machine down. QuickSecure keeps the endpoint calm, responsive, and protected in the background.
Inside the agent
Purpose-built reasoning agents — not a chatbot, not an LLM wrapper. QuickSecure runs as a lightweight native app on every device, with on-device ML inference, network defense, dependency auditing and email security — all in one calm dashboard, with reversible autonomous response built in.
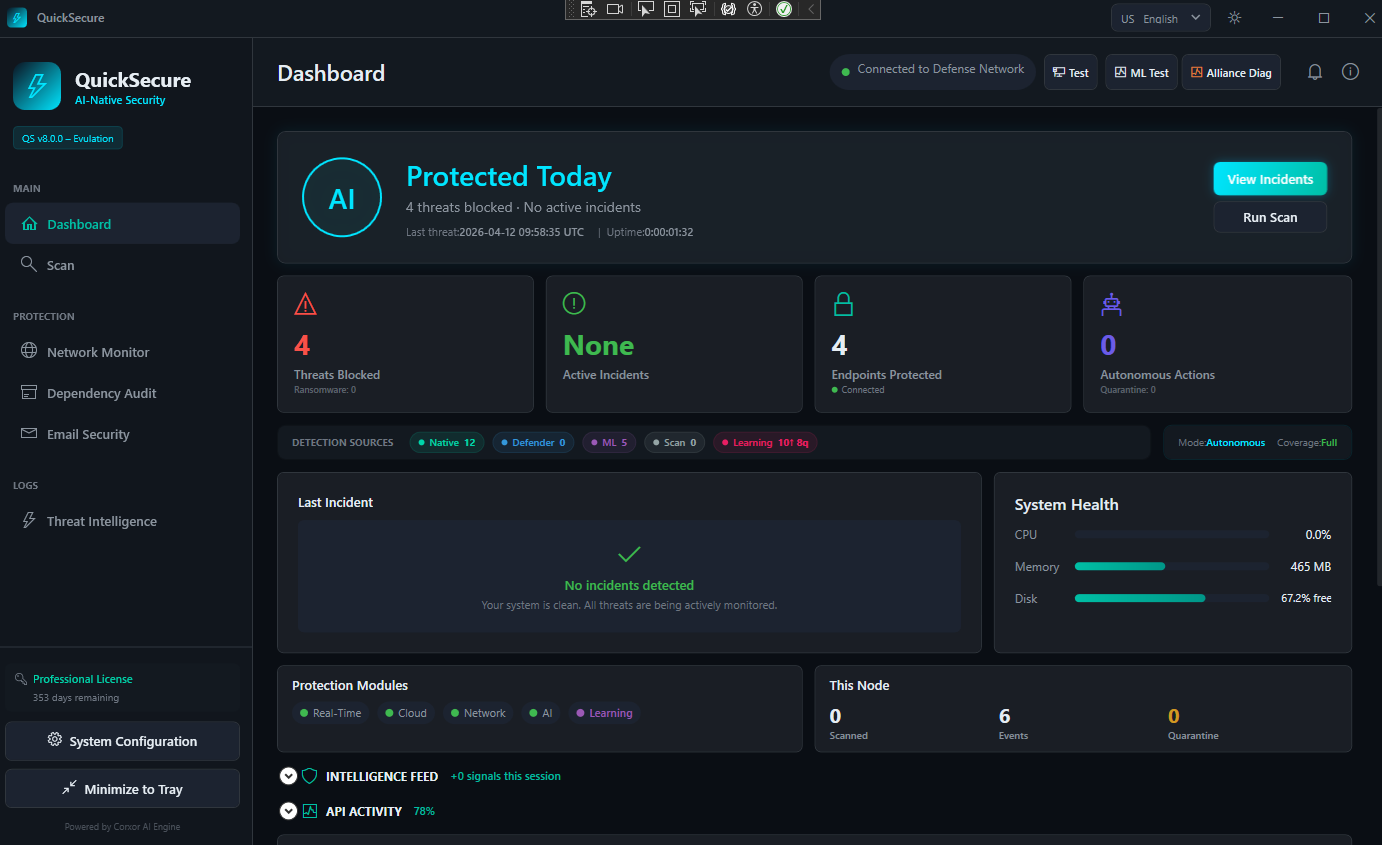
Protected in the background
No alert storms. No confusing dashboards. Just a small signal that your machine is protected.
No action needed
Last event reviewed automatically.
Product tour
A short walkthrough of real-time protection, endpoint visibility, incident response, and AI-assisted security workflows.
Live · Try it now
The same engine that powers incident explanation, IOC assessment and workspace intelligence inside QuickSecure — answering live, right here, against our self-hosted inference.
Real AI inference against our self-hosted model with threat intelligence grounding. Pick an example below or type your own question.
Self-hosted inference. No data leaves our infrastructure. Public demo is rate-limited.
Early access
We are working directly with a limited number of teams that want quieter, smarter endpoint protection.
Join early, deploy QuickSecure with direct founder support, and help shape the product around real-world security needs.
No pressure. No enterprise sales process. Just a direct conversation with the team building it.
For the technical reader
Architecture, ML governance, multi-tenant isolation, operating modes, resilience, deployment options, and the technical FAQ — all in one place for the people who want depth.
Read the platform deep-diveProtection runs on the endpoint.
Built to reduce alert fatigue.
On-device inference. Tenant-isolated. Per-device cryptographic identity.
Built by the team that uses it.
Shaped with early security teams.
Designed to stay out of the way.
One minute to start. No noise to manage. No enterprise sales process required.
Built after a real attack. Designed for calm, intelligent protection.